전체 도메인 설계 부분 중에 Store와 관련있는 부분만 따로 캡쳐하였다.
전체 도메인 그림은 필자의 깃허브 레포지토리로 가면 된다.
https://github.com/hangeulisbest/market
hangeulisbest/market
API 개발 . Contribute to hangeulisbest/market development by creating an account on GitHub.
github.com

모든 가게들의 정보를 요청하면 RESPONSE의 JSON FORMAT은 아래와 같다.
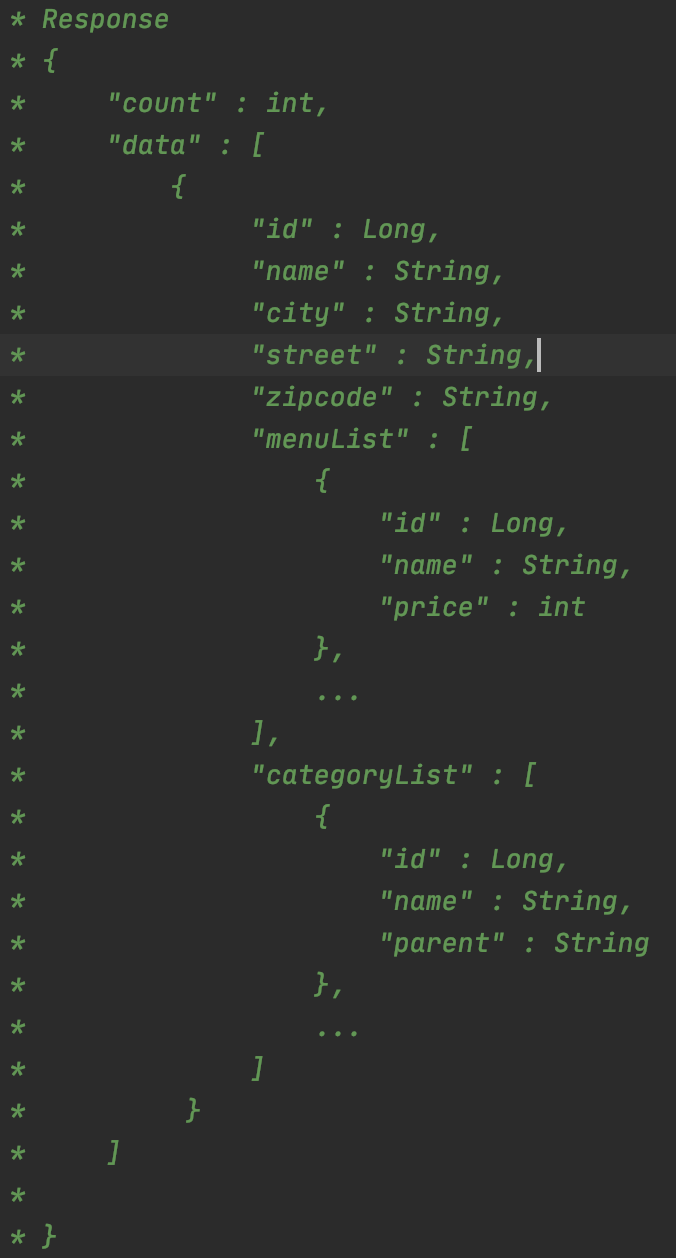
count : 모든 가게들의 개수.
data : 가게들의 리스트.
data/ id : 가게의 pk
data/name : 가게의 이름
data/city: 가게의 도시 주소
data/street: 가게의 거리 주소
data/zipcode: 가게의 우편번호
data/menuList: 가게가 장사하는 메뉴들의 목록 (Menu 객체를 일대다로 참조)
data/menuList/id : 각 메뉴의 아이디
data/menuList/name : 각 메뉴의 이름
data/menuList/price : 각 메뉴의 가격
data/categoryList: 가게가 속한 카테고리 목록
data/categoryList/id : 각 카테고리의 아이디
data/categoryList/name: 각 카테고리의 이름
data/categoryList/parent: 각 카테고리의 부모 카테고리의 이름
version1. 모든 가게들의 정보를 가져와 보자

만약 여기서 모든 Store 데이터를 가져온다면 categoryStore와 Menu에 관한 정보는 어떻게 가져올 것인가?
또 어떻게 위에 제시한 DTO 형태로 적절하게 변환할 것인가?
무식하게 하는 방법을 소개한다.
1. categoryStroe를 가져오는 JPARepository와 Menu를 가져오는 JPARepository와 Store를 가져오는 JPARepository 모두 주입을 받는다.
2. StoreRepository에서 모든 가게를 가져온 다음에 Stream을 이용해 DTO로 변환한다. (단, menuList 와 categoryList는 각각의 Repository를 이용해 모두 조회한다.)
<StoreService에서 Repository로 부터 데이터를 가져와 DTO로 변환하는 작업 코드>
1번과 2번의 과정을 보여주는 복잡하고 지저분한 코드..
@Transactional(readOnly = true)
public StoreListResponseDto findAll2(){
List<Store> storeList = storeRepository.findAll();
List<StoreResponseDto<Object, Object>> collect = storeList.stream().map(o -> StoreResponseDto.builder()
.name(o.getName())
.city(o.getAddress().getCity())
.street(o.getAddress().getStreet())
.zipcode(o.getAddress().getZipcode())
.menuList(
MenuListResponseDto.builder()
.count(menuRepository.findByStore(o).stream().map(
x -> new MenuResponseDto(x.getId(),x.getName(), x.getPrice())
).collect(Collectors.toList()).size())
.data(menuRepository.findByStore(o).stream().map(
x -> new MenuResponseDto(x.getId(),x.getName(), x.getPrice())
).collect(Collectors.toList()))
.build()
)
.categoryList(
CategoryListResponseDto.builder()
.count(categoryStoreRepository.findCategoryStoreByStore(o).stream().map(
x -> new CategoryResponseDto(x.getCategory().getId()
, x.getCategory().getName()
, (x.getCategory().getParent() == null) ? null : x.getCategory().getParent().getName())
).collect(Collectors.toList()).size())
.data(categoryStoreRepository.findCategoryStoreByStore(o).stream().map(
x -> new CategoryResponseDto(x.getCategory().getId()
, x.getCategory().getName()
, (x.getCategory().getParent() == null) ? null : x.getCategory().getParent().getName())
).collect(Collectors.toList()))
.build()
).build()
).collect(Collectors.toList());
return StoreListResponseDto.builder()
.count(collect.size())
.data(collect)
.build();
}
POSTMAN을 이용해 어떠한 쿼리들이 날라 가는지 알아보자.
참고로 카테고리는 3개, 유저는 100명, 가게는10곳 메뉴는 20개로 미리 초기화 시켜 놓았다. 어떻게 초기화 시킨지는 별로 중요하지 않으므로 쿼리가 얼마나 전송되는지에 초점맞춰서 살펴본다.
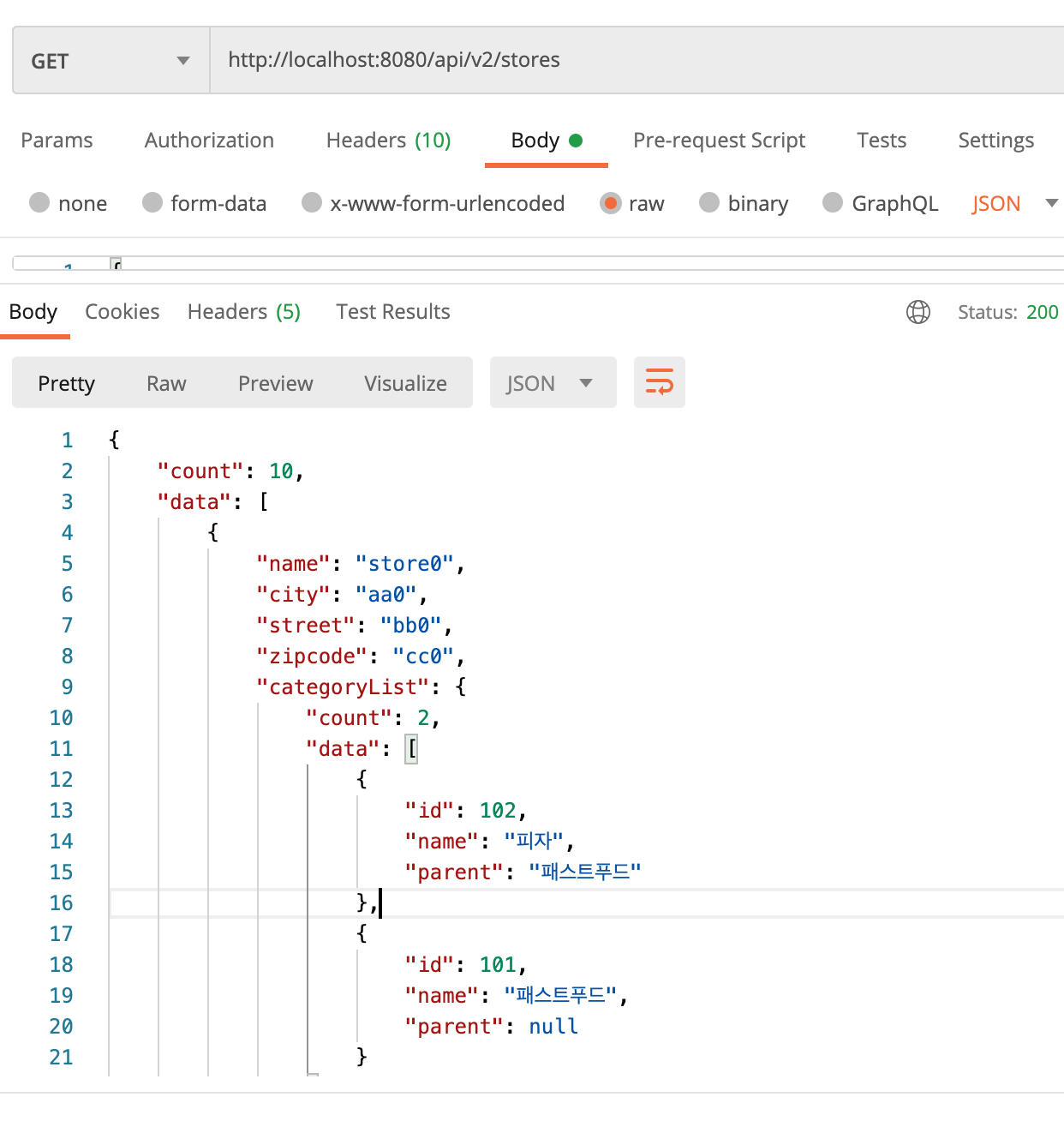
GET 요청으로 /api/v2/stores 로 보내본다.
결과는 잘나온다.
그러나 스크롤의 끝이 보이지 않는 SQL문이 전송되었다. 더많이 전송되었는데 일부분만 보여준다.
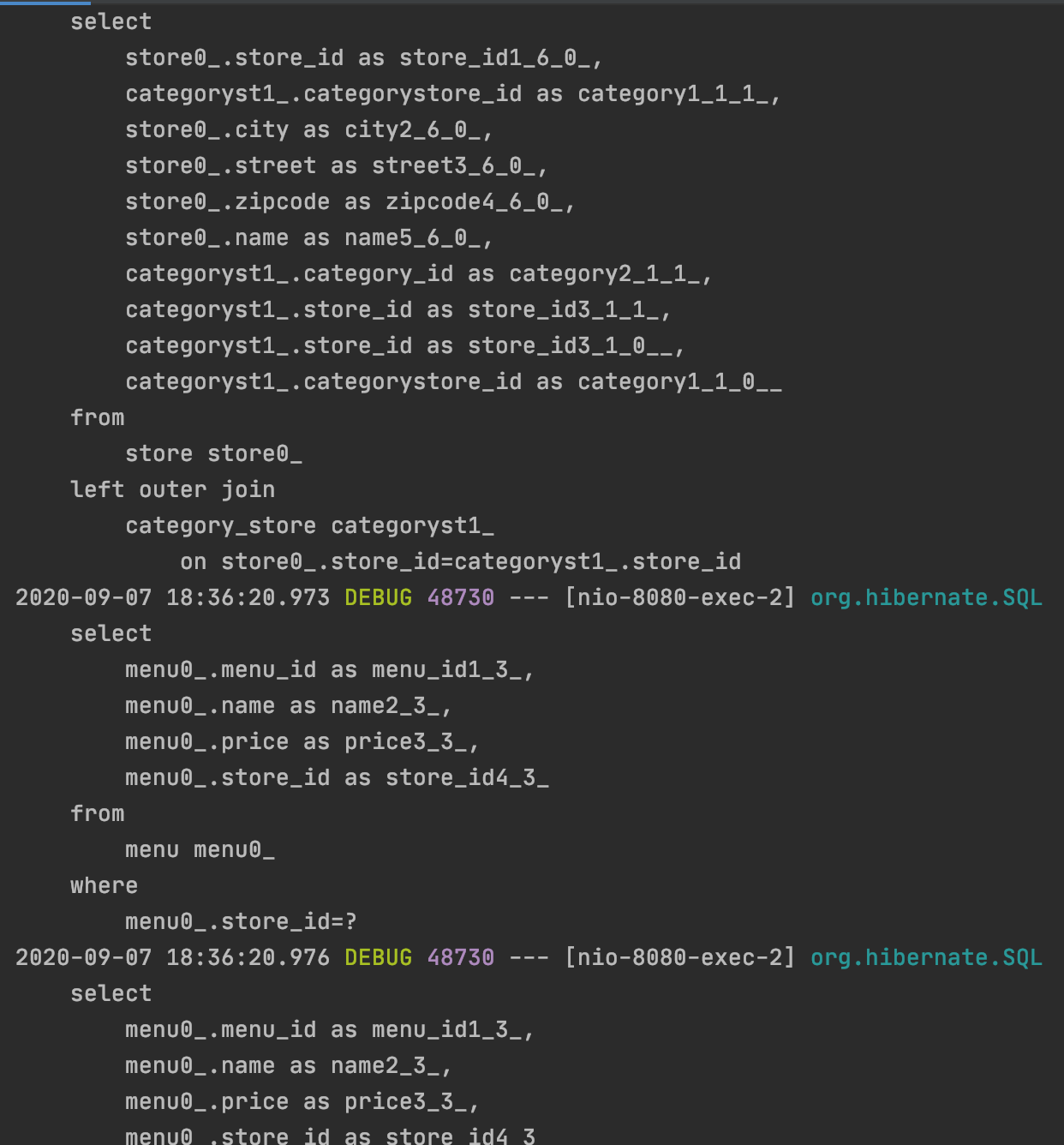
이유는 다음과 같다.
먼저 StoreRepository를 이용해 모든 Store를 가져온다고 해보자. 그러면 menuList와 categoryList도 또한 영속성 컨텍스트에 있을 것인가? 답은 아니다.
menuList와 categoryList는 프록시 객체로서 껍데기만 있는 상황이다.

그래서 categoryStore를 매번 데이터베이스에 접근해서 가져와야 하기때문에
흔히들 이야기하는 N+1 문제가 발생한다. menuList 도 마찬가지다.
이를 version2에서 페치조인으로 해결해 볼것이다.
version2. 페치조인으로 N+1문제를 해결하고 검색조건을 추가하여 동적쿼리를 처리하자.
모든 정보를 가져오는 것에 대해서 의문이 생겼다.
누군가는 카테고리가 패스트푸드인 것만 가져오고 싶어 할 것이며,
누군가는 특정 가게의 이름을 검색해서 가져오고 싶어할 수도 있다.
그래서 검색조건을 넣어서 좀더 깔끔한 조회 API를 만들어 보기로 하였다.
그전에 version1에서 명시한 N+1문제부터 페치조인으로 해결해보자. 그 다음 검색조건을 넣은 깔끔한 코드를 리뷰한다.
모든 가게를 가져오기 위해서 StoreRepository에서 Store를 findALL을 해야할까??
여기서부터 의문을 가졌다. 미리 모든 정보를 다 가져올 수 있으려면 페치조인을 해서 미리 모든 객체를 영속성 컨텍스트에 올려 놔야하는데 Store에서 일대다로 참조하고 있는 카테고리나 메뉴들을 미리 가져올 수 있냐는 말이다.
이는 필자가 한번 다뤘던 일대다 조인에서 카테고리나 메뉴들을 가져올때 문제점을 언급하였다.
https://onejunu.tistory.com/35?category=835844
[JPA] 일대다 조인할때 영속성 컨텍스트 내부 모습 & distinct
엔티티와 데이터베이스를 매핑을 아래와 같이 한다. @Entity class User{ ... @ManyToOne(fetch = FetchType.LAZY ) private Team team; ... } @Entity class Team{ @OneToMany(mappedBy = "team") // 기본적으로..
onejunu.tistory.com
따라서 "일대다"로 참조하고 있다면 "다" 입장에서 fetch join 하는 것이 훨씬 안전하다.
그래서 categoryStore 객체를 기준으로 카테고리와 Store를 모두 가져오고
그다음 Menu 객체를 기준으로 Store를 모두 가져온다. 총 쿼리 2번으로 해결한다.
위 과정을 queryDSL을 이용하여 해결한 코드로 보이면 아래와 같다.
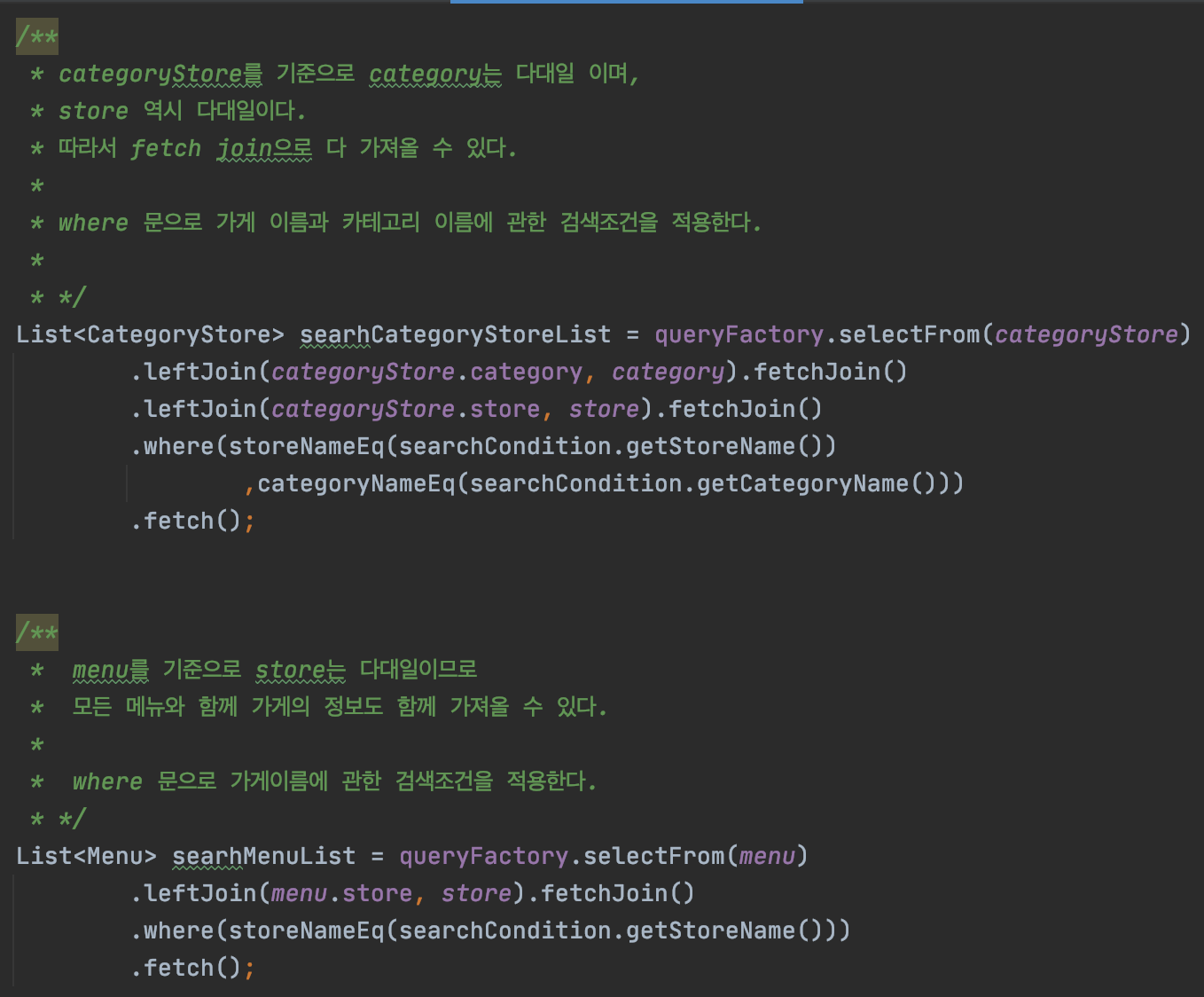
searchCondition 은 검색조건인데, 가게이름과 카테고리이름 2가지를 입력으로 받을 수 있다.
추가로 검색 조건을 검사하는 코드는 아래와 같다.

이렇게 가져온 searchCategoryList 와 searchMenuList 를 활용하여 자바의 스트림을 이용해서 적절한 DTO로 변환해주면 된다.
Version2의 쿼리는 단 2방으로 모든 것을 해결한다.
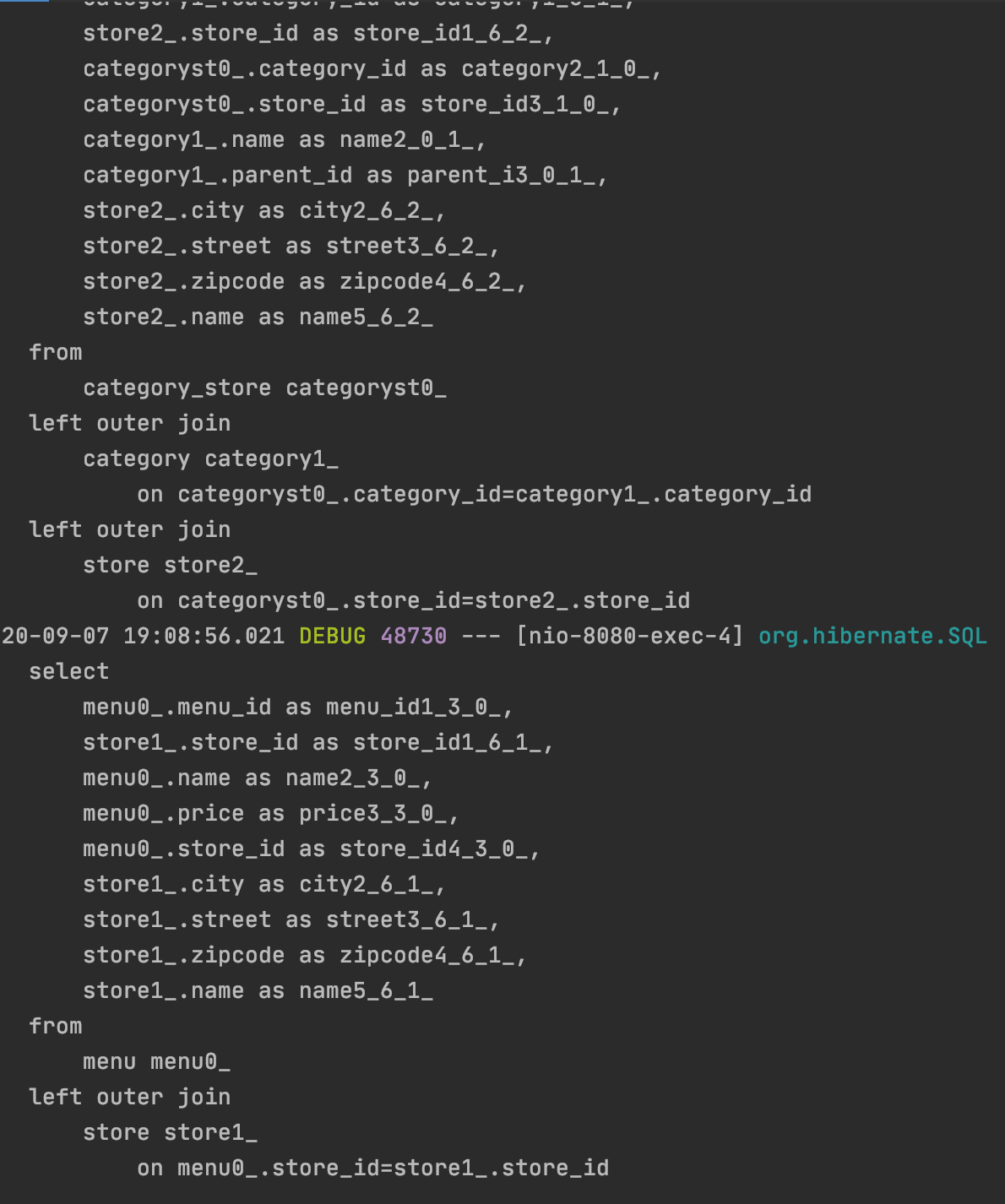

결과도 잘 나오는 것을 확인 할 수 있다.
'Spring' 카테고리의 다른 글
| [일지] List 를 pageable 과 PageImpl 로 구현하기 ( List to pageImpl ) (0) | 2020.09.17 |
|---|---|
| [일지] mustache 에서 javascript 정적 리소스를 불러올 때 GET http://localhost:XXX net::ERR_ABORTED 404 (0) | 2020.09.15 |
| [일지] Category는 삭제할 수 없다고?? (0) | 2020.09.02 |
| [일지] Static 메서드로 생성하는 객체가 자동으로 save?? (0) | 2020.09.01 |
| [일지] TestRestTemplate 로 테스트 하면서 궁금했던 점(feat :NoSuchBeanDefinitionException) (0) | 2020.09.01 |




댓글