kNN 알고리즘을 사용하여 농구선수의 포지션을 예측해보자.
1. 데이터 살펴보기
read_csv() 함수를 통해 csv파일을 데이터프레임형으로 저장합니다.
경로의 뜻은 이전디렉토리로가서 csv 폴더를 찾고 basketball_stat.csv 라는 파일을 지칭한 것입니다.
csv 파일에 대해 더 자세히 알고싶으시면
https://ko.wikipedia.org/wiki/CSV_(%ED%8C%8C%EC%9D%BC_%ED%98%95%EC%8B%9D)
CSV (파일 형식) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. CSV(영어: comma-separated values)는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일이다. 확장자는 .csv이며 MIME 형식은 text/csv이다. comma-separated variables라고도 한다. 오래전부터 스프레드시트나 데이터베이스 소프트웨어에서 많이 쓰였으나 세부적인 구현은 소프트웨어에 따라 다르다. 그것들을 추가한 형태가 2005년 10월 RFC 4180에서 Inf
ko.wikipedia.org
데이터를 출력해봅시다.

4번줄 = head() 라는 함수를 이용해 데이터의 맨위 상단 5개만 뽑습니다.
속성 설명
Player : 플레이어의 이름
Pos: 플레이어의 포지션을 나타냅니다. 'SG' 는 '슈팅가드' 'C'는 '센터'를 의미
3P : 평균 한 경기 3점슛 성공 횟수
2P : 평균 한 경기 2점슛 성공 횟수
TRB: 평균 한경기 리바운드 성공 횟수
AST: 평균 한경기 어시스트 성공 횟수
STL: 평균 한경기 스틸 성공 횟수
BLK: 평균 한경기 블로킹 성공 횟수
5번줄 = Pos라는 속성의 각 속성의 이름과 개수를 반환합니다.
2. 데이터 시각화
데이터가 어떻게 분포하는지 그래프로 확인해 봅니다.

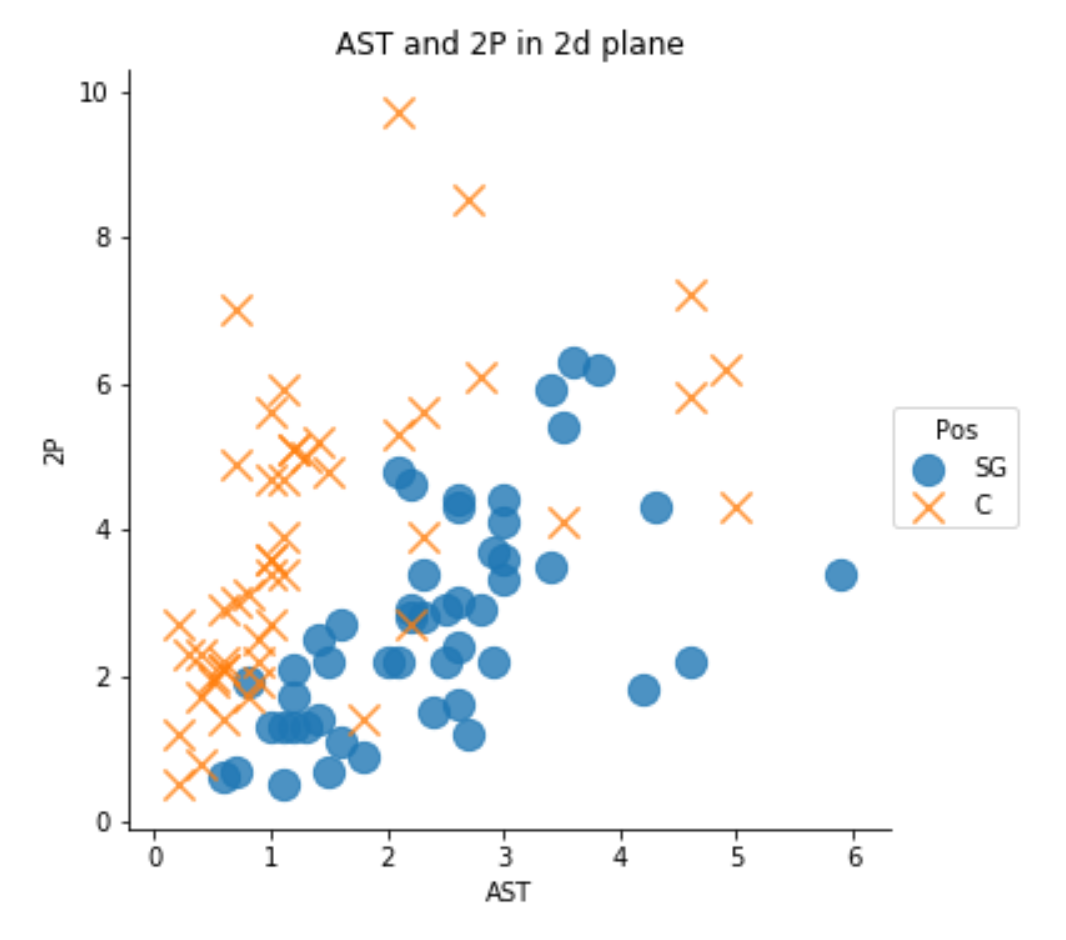
다른 속성들과 포지션도 비교해봅시다.

3. 데이터 다듬기
데이터를 살펴보니 AST ,STL, 2P 라는 속성이 Pos(포지션) 을 예측하는 데 별 도움안되는 것 같습니다.
3가지 속성을 없애버리고 나머지 속성을 씁니다.

4. 데이터 나누기
학습 데이터와 테스트 데이터로 나누어 봅시다.

5. 최적의 kNN파라미터 찾기 (k찾기)

사용법 : cross_value_score (모델이름, 학습데이터 , 레이블 , cv값 )
코드를 이해하기 편하게 하기 위해 데이터를 먼저 출력해봅시다.


위의 코드를 이해해봅시다.
max_k_range 는 k의 최대 크기를 지정합니다.
k는 해당하는 데이터의 위치로 부터 k개의 다른 데이터의 label을 살펴보기 위한 것입니다.
k는 주로 홀수로 지정합니다. 왜냐하면 짝수로 지정하면 무엇으로 선별할지 애매한 경우가 생기기 때문입니다.
예를 들면 어떤 데이터의 주변에 2개의 슈팅가드가 있고 2개의 센터가 있다면 이 데이터는 무엇으로 결정해야
할까요? 따라서 k는 홀수로 지정합니다.
따라서 k_list 는 3부터 시작해서 5,7,9, ... 가 들어갈 것입니다.
cross_validation_scores 는 교차검증의 점수들의 리스트가 될 것입니다. 나중에 이중에서 가장 큰 점수를 가진
k값을 훈련시키는 데 사용할 것입니다. 아직 훈련하지 않았습니다!

k_list의 각각의 값들을 순회하면서
knn 에 KNeighborsClassifier() 모델을 지정합니다.
scores 에 cross_val_score() 의 리스트를 저장합니다.
cross_val_score()의 파라미터를 보면 knn은 모델명 , x_train은 학습데이터 , y_train.values.ravel() 은 학습데이
터의 레이블을 1차원화 시킨 것입니다. cv는 학습데이터를 10개 분할하여 그중 1개를 검증데이터로 사용하겠다
는 의미입니다. 교차검증이 이해가 되지 않는 다면 이전글을 참조하시기 바랍니다.
10번의 검증을 거치기 때문에 scores 는 10개의 점수가 들어있는 리스트일 것입니다.
scores.mean() 은 10개의 리스트값의 평균을 반환합니다.

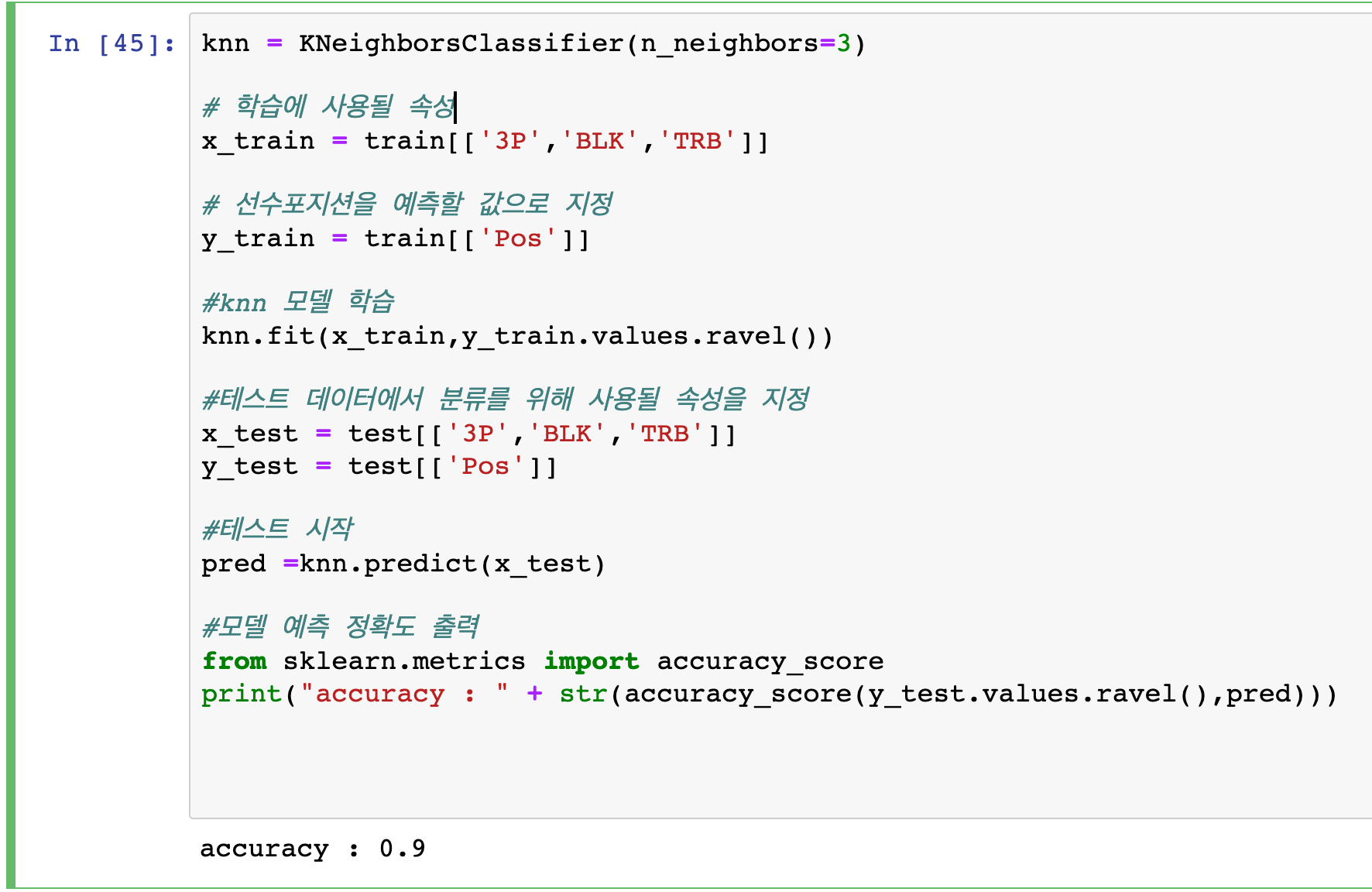
6. 학습 및 테스트 해보기
'Machine Learning' 카테고리의 다른 글
| [머신러닝] 기초 용어 및 개념 (2) | 2020.01.08 |
|---|

댓글